
Behind AI Sequencing: Rising Above Nested Parallelism


Background
At the core of our newest product, Nooks’ AI Sequencing, are AI signals. These AI-driven signals dive deep into each GTM account, uncovering intelligence like the company’s current tech stack, recent leadership hires, and shared investors. This resulting research powers much of AI Sequencing’s functionality, from automating account research to generating personalized AI emails and real-time call scripts.
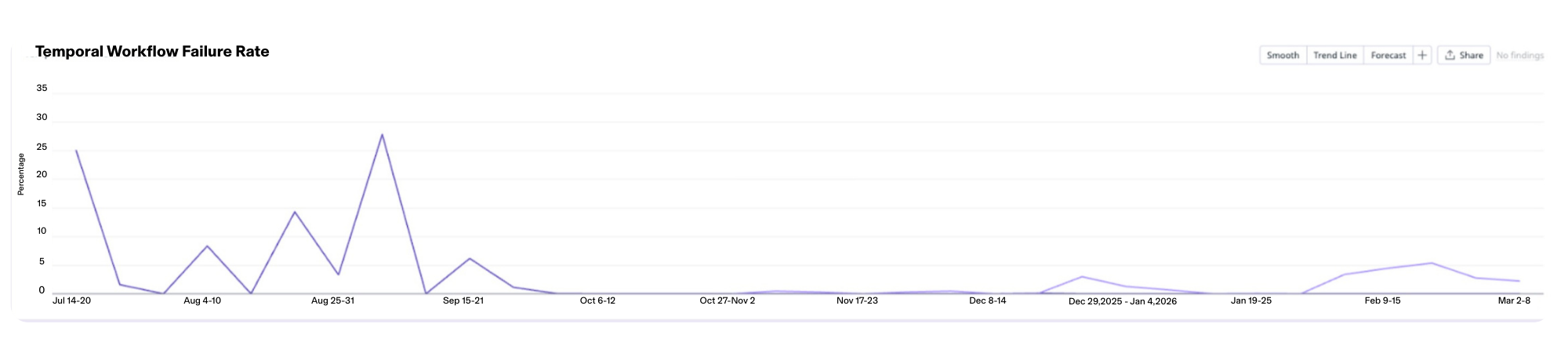
Unfortunately, as we began testing this vision to handle massive customer account books, our AI signals pipeline reached an architectural "ceiling”. At its peak in testing, we saw pipeline failure rates reach a high of 25%, creating downstream bottlenecks across the product.
This post walks through how we finally discovered the subtle scheduling conflicts sabotaging our AI signals, and re-architected the pipeline to the <1% failure rate that AI Sequencing proudly sits on top of.
Initial Assessment
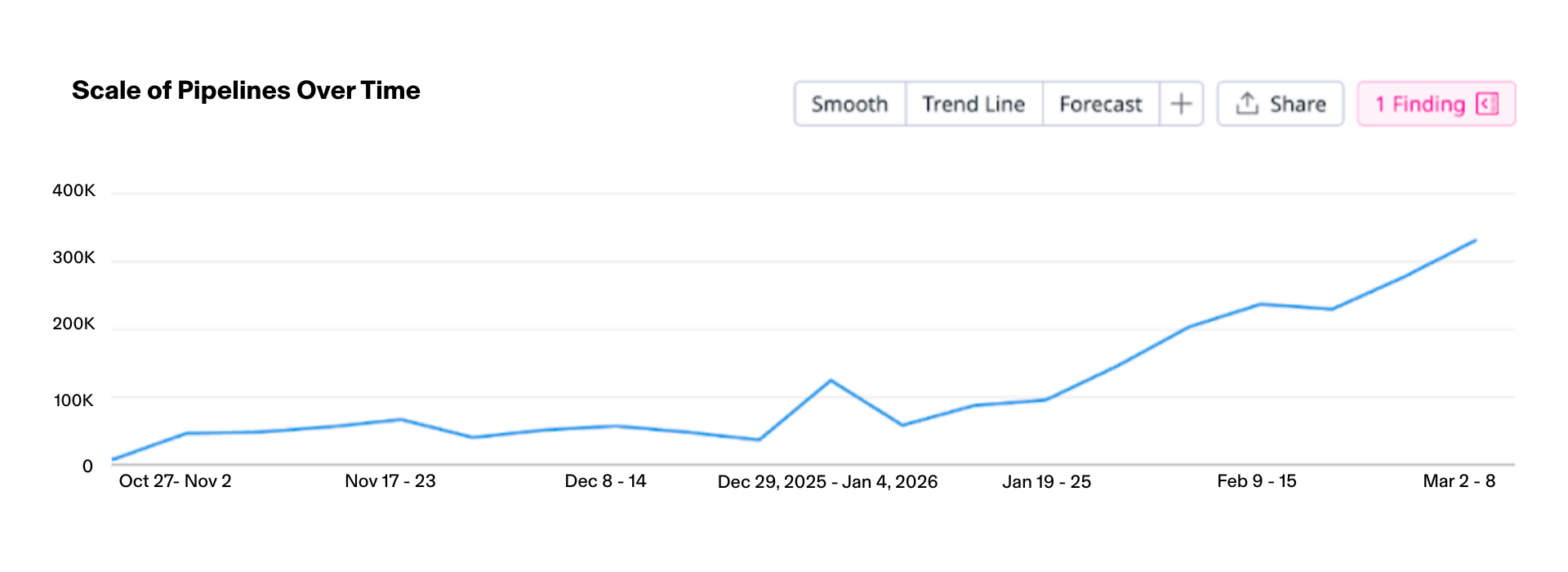
Many large Nooks jobs, including the AI signals pipeline, run on Temporal. Our original AI signals job was huge, processing upwards of 10,000 accounts for a company’s book of business at once.
Consequently, many of these job runs were running into heartbeat timeouts. (Heartbeat timeouts occur when the individual workers running activities fail to communicate their progress to the Temporal orchestrator.)
These heartbeat failures were particularly harmful and hard to debug for a few reasons:
- Retry Exhaustion: While heartbeat timeouts can be retried, they cause slowdowns and eventually failures when retries are exhausted.
- Noisy Failure Signals: The failures were inconsistent. Some seemed to be related to workers restarting, either from expected redeployments or unexpectedly hitting resource limits.
- Event Gaps: Our event loop monitor was detecting many delayed heartbeats, while others seemed to be completely missing. Confusingly this was happening despite no large synchronous code blocks or large fan-outs.
Discovering Event Loop Saturation
Immediately, we made a couple quick fixes to trace and fix the heartbeats. First, we batched the data pulled from the database, eliminating excessive memory usage as a failure case. Then, as recommended by Temporal engineers, we added resource based scheduling to try to reduce CPU usage on a single worker. We also increased the heartbeat frequency, timeout, and scaled up the CPU of our workers. Despite these fixes, we were still missing heartbeats and we weren’t sure why. Auditing the code, we couldn’t find any long running synchronous code blocks and we could see through logs that we were continuously processing activities. This “ghost” failure of the heartbeats not sending continued.
However, we soon realized the root cause was due to an interaction between Node.js task queue scheduling and nested parallelism. While the parallelism at any level was reasonable, nested parallelism was multiplying to create a very high aggregate parallelism.
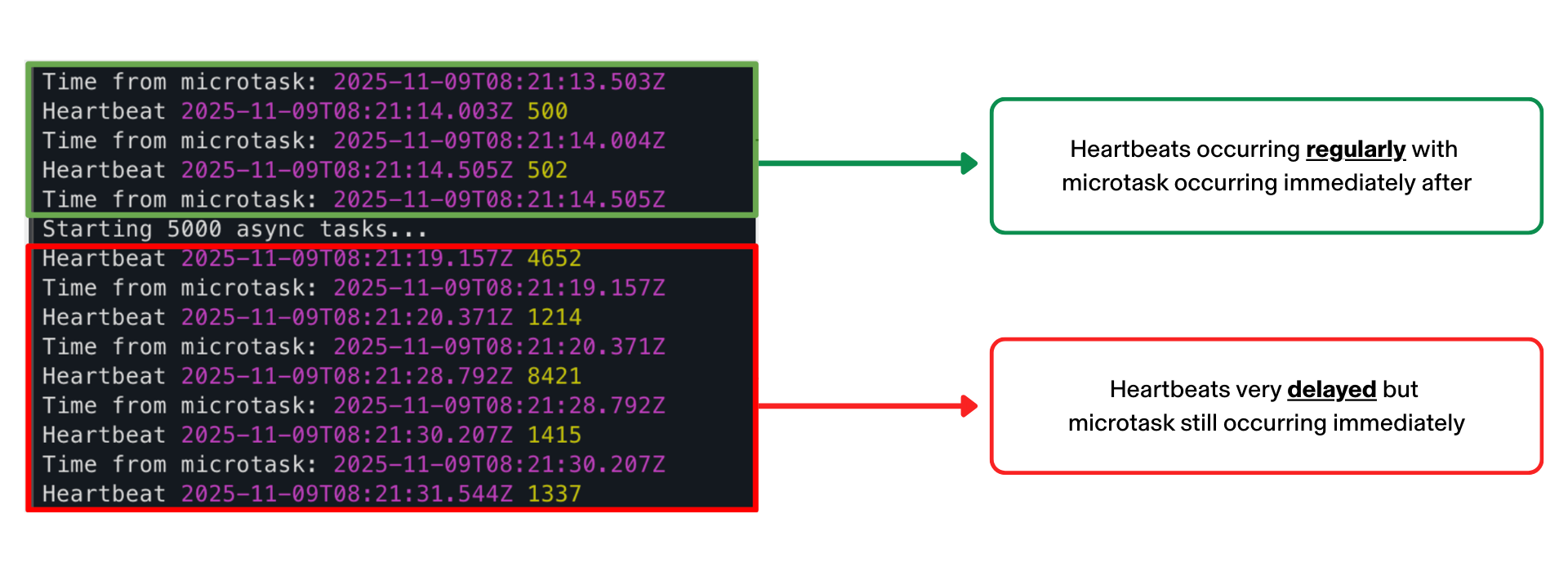
Since JavaScript is single-threaded, the high parallelism was saturating the event loop, a problem compounded by the fact that our heartbeat code was creating a macrotask which would only be scheduled when the long queue of microtasks was complete.
The Solution
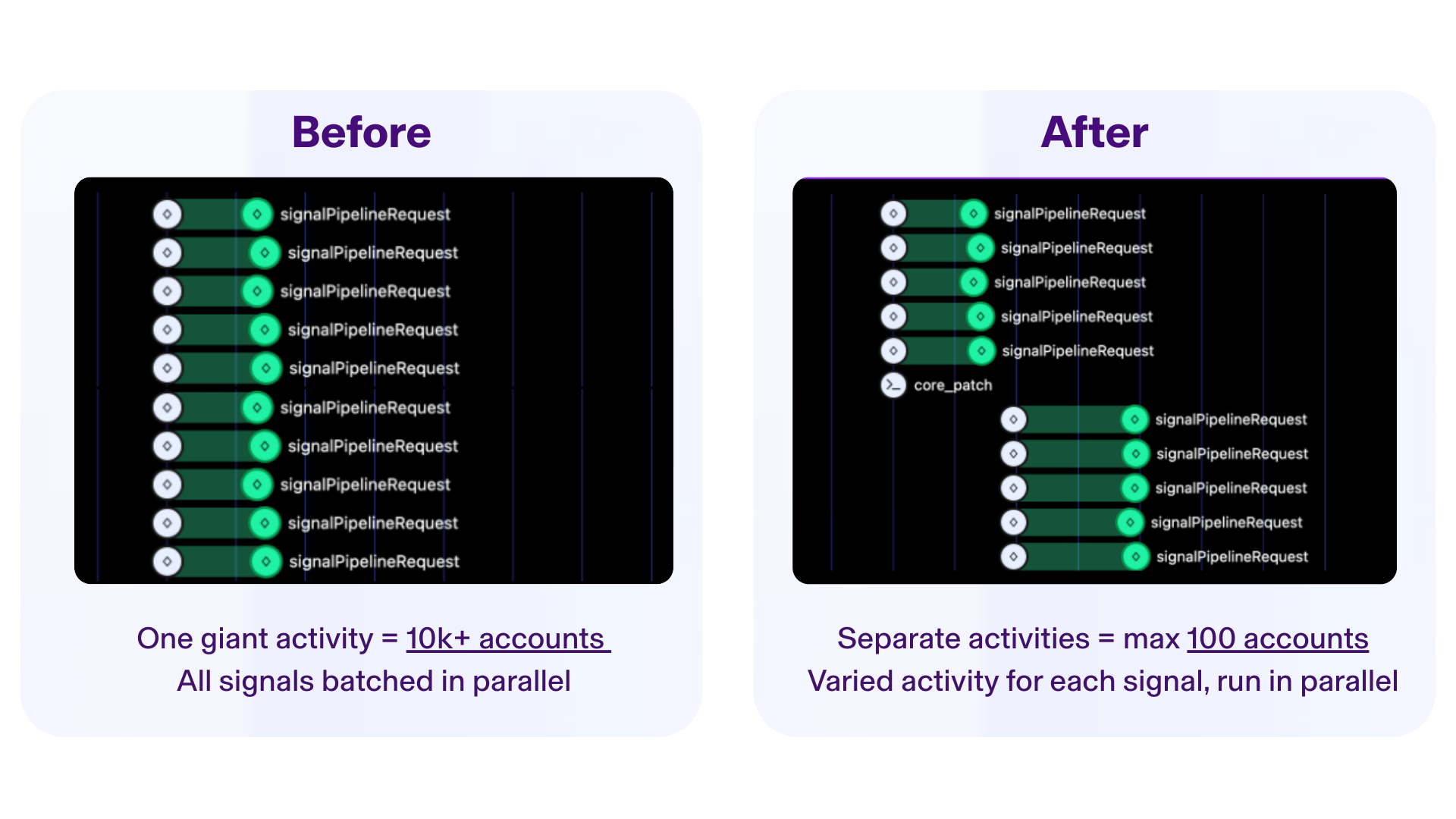
With this understanding, we now confidently pursued splitting up our one large job into smaller activities to reduce the saturation. Smaller activities also had the added benefits of better monitoring, retrying and scaling, all of which Temporal brings out of the box.
Since our job was already highly parallel, we could easily move our concurrency limits upstream. So, we split off smaller activities, like loading data and updating the frontend, and limited our main processing activities to handle a max of 100 accounts and a single signal. A fixed maximum processing size per activity gave us confidence that continued expanding scale wouldn’t cause these same issues in the future.
Second-Order Fixes
Moving to a more distributed model was a win, but it introduced some new error conditions. So for the last two pieces of the puzzle, we fixed-
- gRPC Data Limits: Since we were now running many activities in parallel, each of which required data to be passed in, we started to run into gRPC limits on the total amount of data that we were sending. To prevent this, we started storing our data externally in Google Cloud Storage, ensuring the data size passed to a job was fixed (a single GCS file handle).
- LLM Spend: We also realized we would often start multiple overlapping signal jobs at similar times. While signals outputs were cached, these parallel jobs would often race to produce (and cache) an output, multiplying our running activities and LLM spend. To prevent this, we added a global Redis lock at the level of a single signal running on an account.
Final Results
In the end, we made such great improvements that even we were surprised by just how much impact these changes had made. Our error rates were down to <1% and our P95 and average workflow times were cut in half.
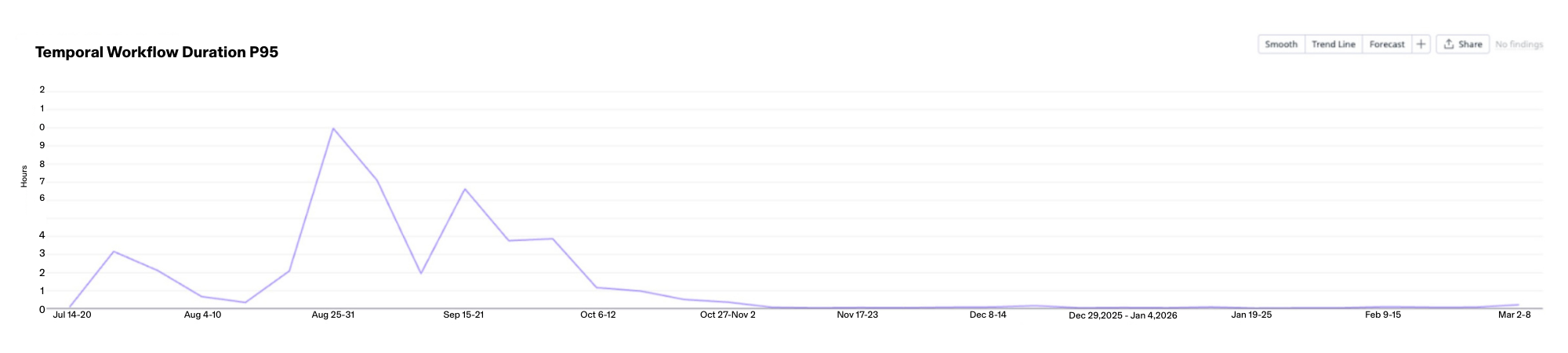
What started as mysterious heartbeat timeouts turned into a lesson in how nested async operations can break systems in non-obvious ways:
- Aggregate parallelism compounds in non-obvious ways causing multiplicative effects. This can be especially dangerous as systems grow and parallelism is added at different levels by different stakeholders to solve different issues.
- Microtask vs macrotask scheduling matters. In high-throughput async systems, critical operations (like heartbeats) can be starved if they're scheduled as macrotasks while thousands of microtasks are generated.
- As systems grow, bounded data sizes give predictability. Limiting the amount of data passing through a system makes reasoning and testing worse-case parallelism much easier.
So, even as the number of total accounts has doubled since testing to launch of AI Sequencing, our pipeline solution has shown lasting reliability. Here's to the next million accounts as Nooks grows the Agent Workspace for Sales.


.png)
.png)
.png)