AMD 2


Most outbound calls never reach a human. At scale, sales teams in the U.S. waste hundreds of millions of hours each year on rings, voicemails, and phone menus. If you could automatically filter out those machine responses, you could recover that lost time. However, discerning a human from a machine in real time is a deceptively hard problem. You have only the first hundred milliseconds of speech to accurately decide whether to connect the call before latency becomes noticeable.
We built a system that makes this decision millions of times a day, outperforming humans in both speed and accuracy. Getting there required careful data bootstrapping, a low-latency architecture, and a tunable decision engine we can position anywhere along the precision–recall–latency surface. This post walks through how we designed and tuned that system end-to-end.
Scaling Data Without Sacrificing Quality
The core problem is deciding, in real time, whether to hold, hang up, or connect as the call unfolds. Our model buffers audio packets from Twilio, making a prediction every 100 milliseconds to produce a sequence of probabilities that drive the final decision.
We built a manually labeled dataset of over 40,000 calls, splitting each call recording into segments and tagging them by audio type (speech, silence, voicemail, hold music, and so on). Models trained on this data achieved good precision and recall but were too slow to make high-confidence decisions in real time, resulting in a system that was not yet viable for production. To meet our accuracy and latency targets, we needed to expand the dataset by at least two orders of magnitude.
To scale up, we ran the baseline model on 10 million production calls, running inference throughout each call to capture how it unfolded. Self-labeling at this scale inevitably introduced noise, so we needed a way to separate clean data from uncertain examples. To do that, we built an ensemble with a multimodal LLM, running it on the same 10 million calls for independent classification. When both models agreed on the top-level call type, around 80% of the time, we treated those labels as high confidence and ended up with a filtered dataset of roughly 8 million calls.
With a reliable top-level classification, we could start injecting domain knowledge to fix segment-level errors. The ensemble predicted call type acts as a prior that constrains what patterns are possible, effectively turning each call type into a simple finite-state machine.
For example:
- Voicemail calls follow a predictable structure: greeting → beep → silence. If both models agree a call is voicemail, we can safely reclassify “human” segments before the beep as greeting content.
- Phone tree calls shouldn’t contain voicemail segments early on; those are usually prompts misclassified due to similar acoustic features.
- Human calls let us validate patterns like hold music or confirm that detected speech is actually conversation.
We applied similar domain-specific corrections for other call types. Calls that didn’t fit the expected pattern—whether due to poor baseline predictions, segmentation errors, or edge-case behavior—were filtered out entirely. The ensemble agreement gave us the confidence to apply these rules without over-correcting ambiguous cases.
In the end, we produced about 7 million high-quality labeled calls, representing a 200× increase over our initial manual labeling effort. Spot checks confirmed quality on par with human-annotated data.
Using this dataset, we retrained our baseline model, combining a pre-trained audio encoder with Mamba state-space layers. Mamba’s linear-time complexity keeps inference lightweight and latency predictable even as calls run long, which is critical for tasks like navigating phone trees or detecting voicemail beeps in real time.
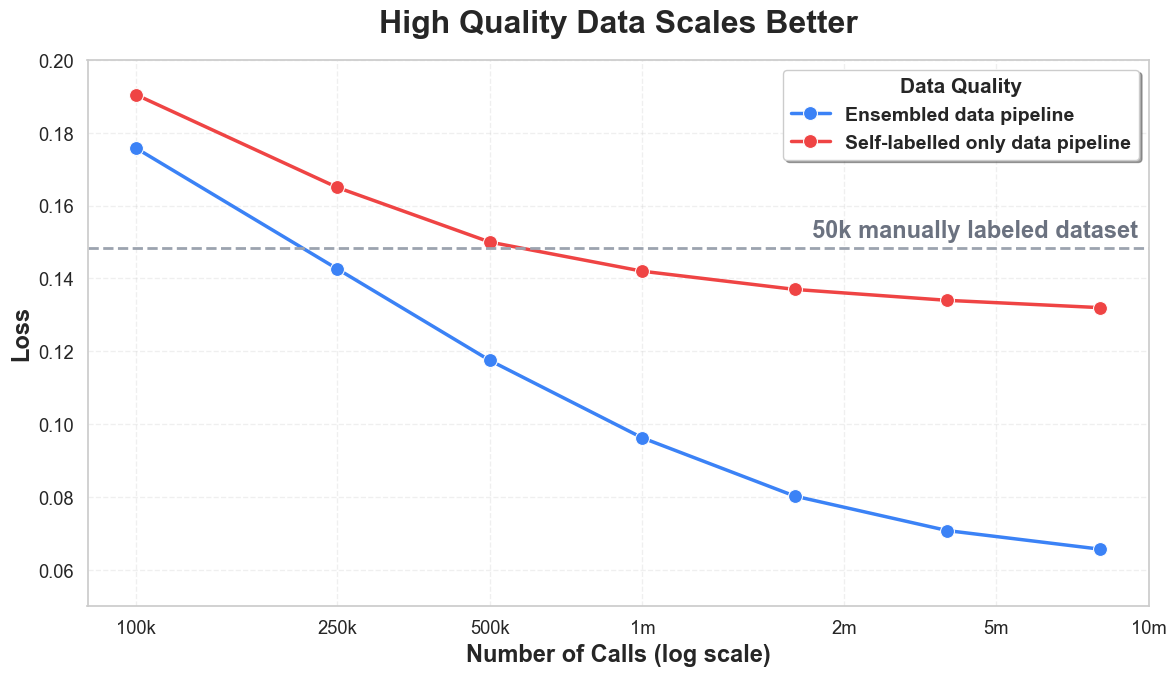
Ablations on our data preprocessing pipeline highlighted the importance of ensuring data quality. Lower quality datasets reached a performance asymptote at a lower dataset scale. Increasing dataset size only helps if the labels are of high enough quality to provide signal for difficult samples.
From Predictions to Decisions
Training the model was only part of the challenge. Once we had reliable frame-level predictions, the next question was how to turn those probability sequences into timely, application-specific decisions for each call. If The right balance between speed, precision, and recall depends entirely on context. We use the same underlying model for several distinct workflows, each with its own trade-offs:
- Parallel dialing: We dial multiple lines at once and connect only when a human answers. Because the default state is disconnected, we tune for precision — a false connect interrupts other active calls and hurts the experience. We also minimize latency for real humans, since the rep can’t respond until the connection completes.
- Power dialing: We place calls one after another, keeping each line connected by default. Here we tune for recall, since the risk of hanging up on a real person outweighs the cost of a false positive. Latency still matters, because faster detection lets reps move on more quickly when a call reaches a machine.
- Beep detection: After a call connects, we detect the beep that signals when to start leaving a message. Latency is more forgiving, but both precision and recall need to stay high to ensure pre-recorded voicemails drop at the right time.
A single confidence threshold is often enough to get reasonable results, but it leaves you far from the optimal trade-offs between latency, recall, and precision. Maximizing performance requires more flexibility, for example firing quickly at very high confidence or waiting longer when the signal is weaker.
To handle that, we built a decision layer that can run any number of detectors in parallel, each defined by a simple set of parameters like threshold, window size, and decision delay. Each detector evaluates the model’s probability stream and triggers when its defined conditions are met. This setup makes it easy to fine-tune behavior for different workflows without changing the underlying model or code.
Every workflow has its own configuration tuned for its goals. We optimize these configurations by replaying a large, uniformly sampled set of production traces through the decision layer exactly as it does in production. The simulator feeds in the model’s streaming outputs frame by frame and records when each detector would have triggered. We then use multi-objective optimization to search the parameter space of the defined detectors and identify configurations that achieve the best latency-recall-precision trade-offs for each workflow.
In production, the system now makes these decisions millions of times a day, connecting people in real time. Since launch, we’ve seen recall improve by 7%, precision by 9%, and median latency drop by more than 200 ms. Bringing beep detection in-house also cut more than $7k from our monthly Twilio bill.
There is much more that goes into building a seamless dialing experience. In future posts, we’ll dive into topics like navigating phone-trees in real time with LLMs, optimizing infrastructure for latency at scale, and pretraining audio encoders on large unlabeled datasets to improve generalization across call types.
If working on streaming ML and real-time systems that ship at production scale is interesting, this is a good place to build.